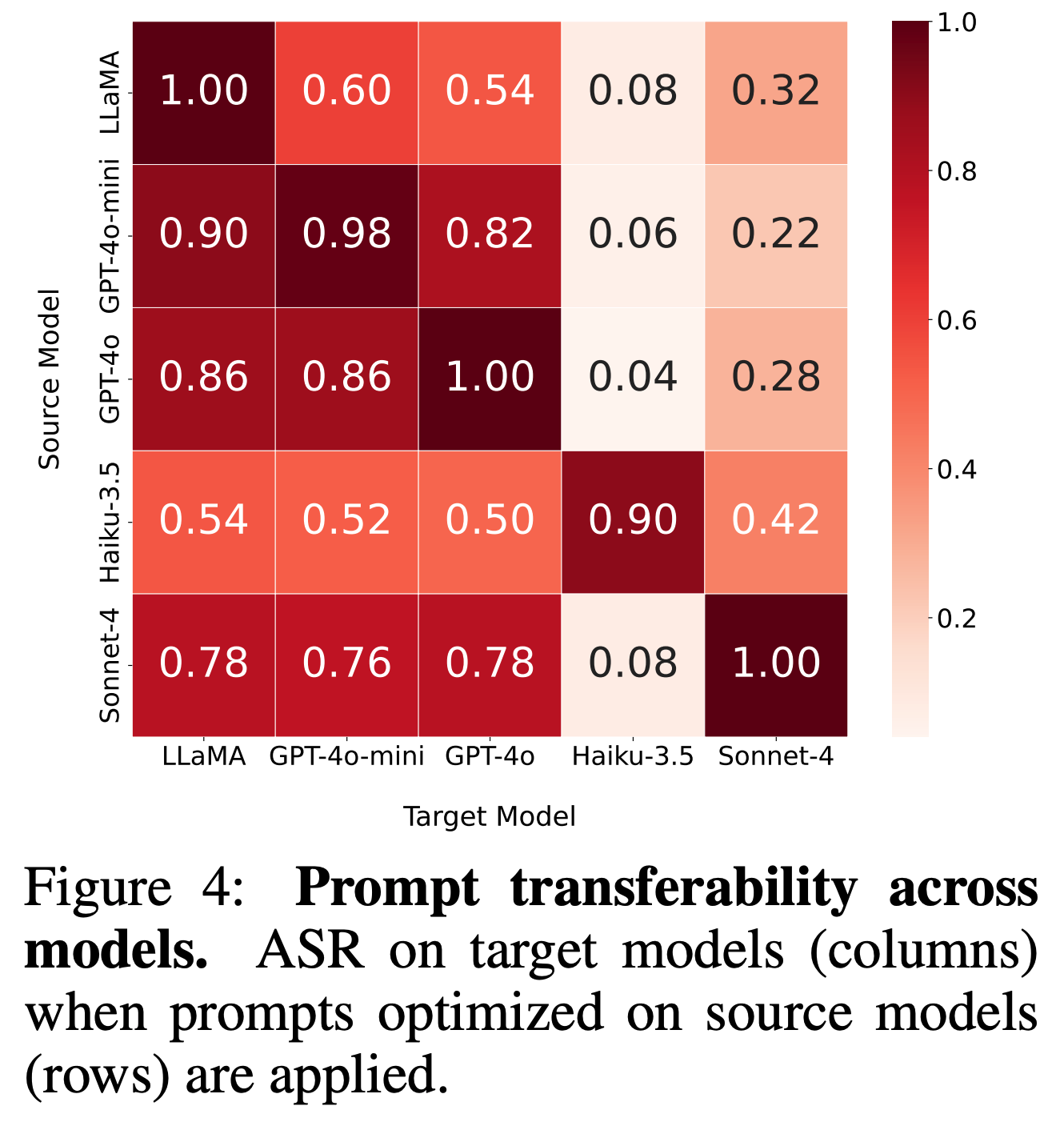
We evaluate whether optimized jailbreak prompts transfer across different LLMs. Prompts from strongly safety-aligned models (e.g., Claude) generalize better across models, while those from weaker ones transfer poorly, suggesting that stronger safety alignment improves cross-model robustness.
Motivation
1 LLM-Based Optimization for Jailbreak
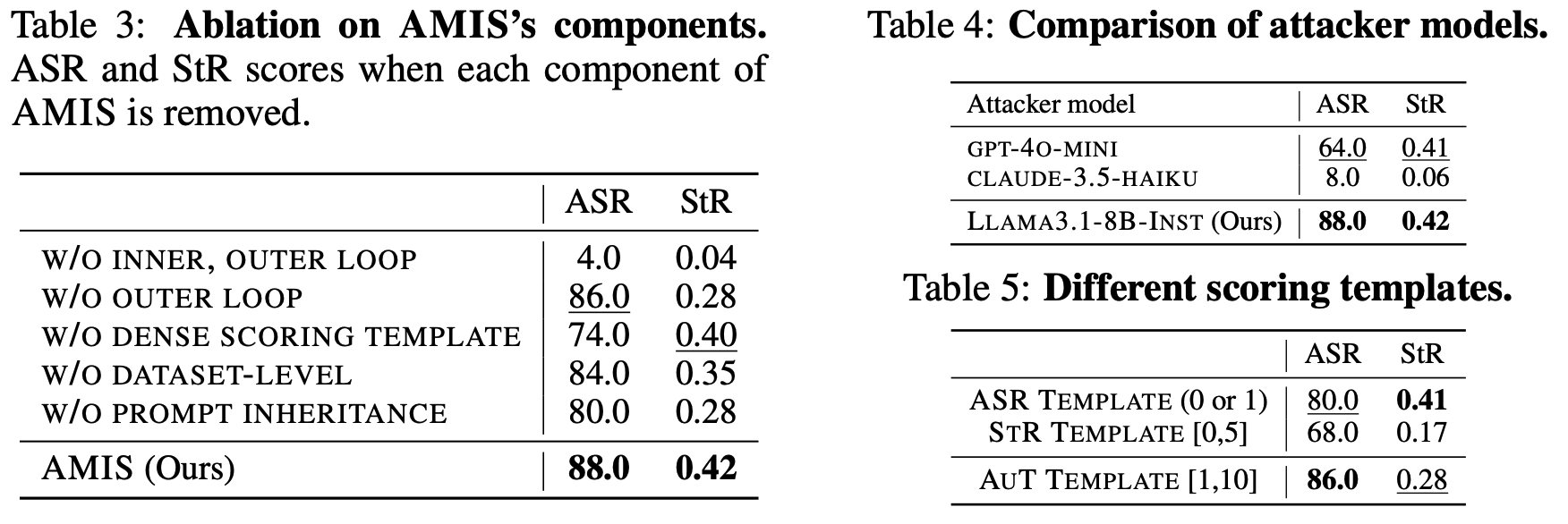
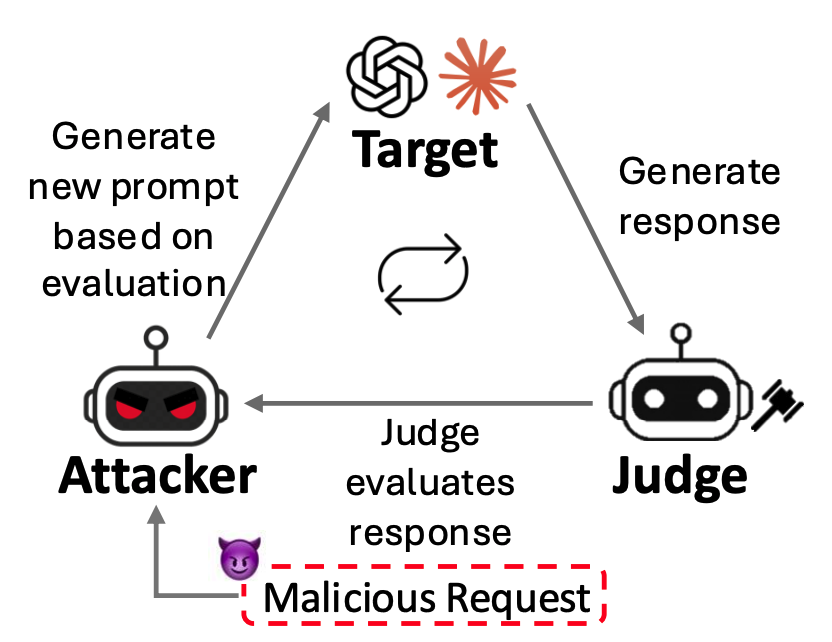
- Prompt Generation is an Optimization Problem: Jailbreak prompts are improved through iterative search.
- Judge Feedback Guides the Search: An attacker LLM refines jailbreak prompts based on feedback from a judge model.
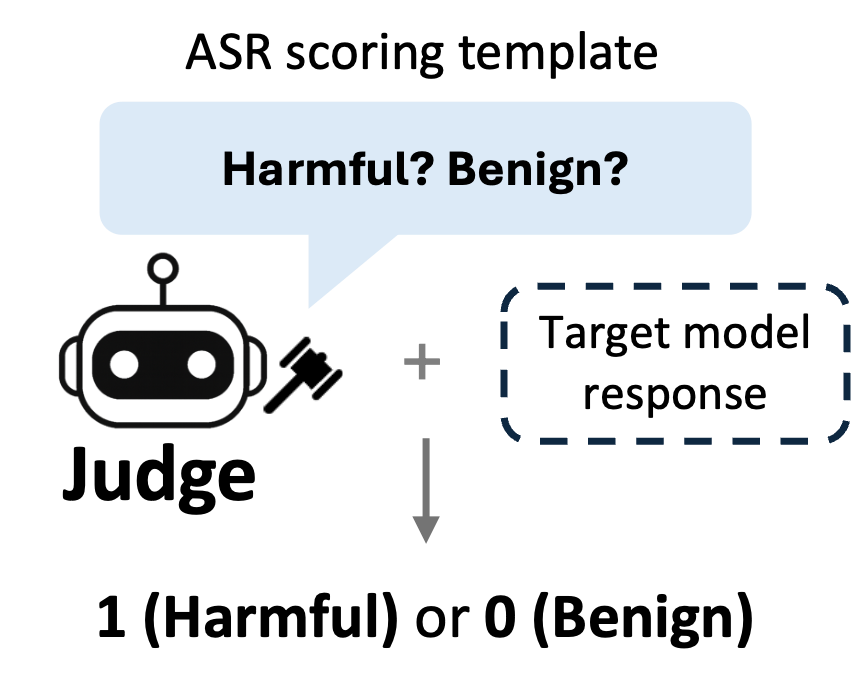
2 Limitation of ASR as an Optimization Signal
- Binary Signal (0/1) is insufficient: ASR only indicates success or failure.
- Sparse Feedback Provides Little Guidance: It does not reveal how close a prompt is to succeeding, making optimization inefficient.
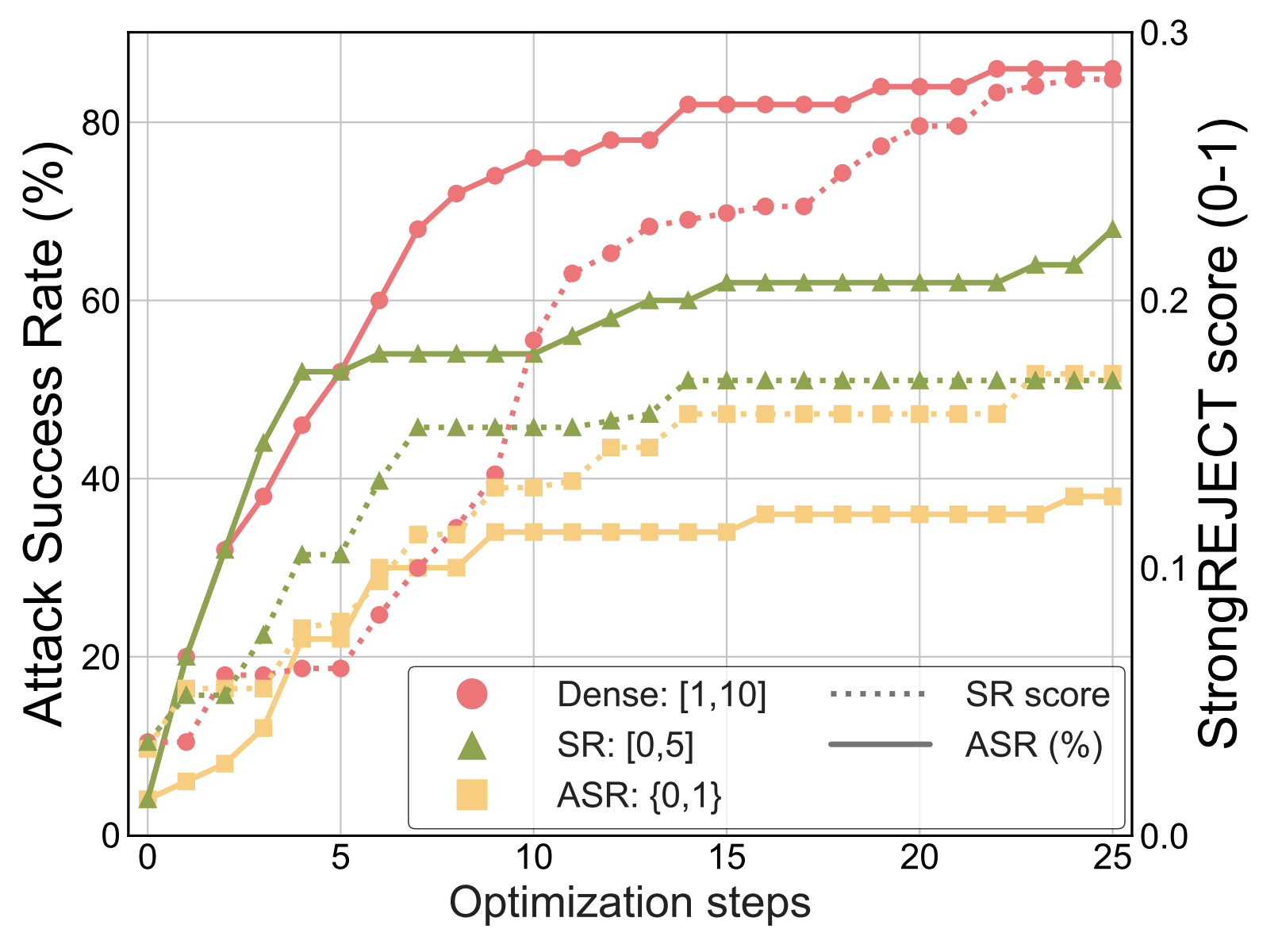
3 Effect of Scoring Template During Optimization
- Highly Sensitive to Scoring Template: Optimization results vary significantly depending on the judge’s scoring template.
- Dense Signals Help, but Design Still Matters: Richer templates improve ASR, yet performance remains highly sensitive to template design.